Dask Release 0.15.0
This work is supported by Continuum Analytics and the Data Driven Discovery Initiative from the Moore Foundation.
I’m pleased to announce the release of Dask version 0.15.0. This release contains performance and stability enhancements as well as some breaking changes. This blogpost outlines notable changes since the last release on May 5th.
As always you can conda install Dask:
conda install dask distributed
or pip install from PyPI
pip install dask[complete] --upgrade
Conda packages are available both on the defaults and conda-forge channels.
Full changelogs are available here:
Some notable changes follow.
NumPy ufuncs operate as Dask.array ufuncs
Thanks to recent changes in NumPy 1.13.0, NumPy ufuncs now operate as Dask.array ufuncs. Previously they would convert their arguments into Numpy arrays and then operate concretely.
import dask.array as da
import numpy as np
x = da.arange(10, chunks=(5,))
# Before
>>> np.negative(x)
array([ 0, -1, -2, -3, -4, -5, -6, -7, -8, -9])
# Now
>>> np.negative(x)
dask.array<negative, shape=(10,), dtype=int64, chunksize=(5,)>
To celebrate this change we’ve also improved support for more of the NumPy ufunc and reduction API, such as support for out parameters. This means that a non-trivial subset of the actual NumPy API works directly out-of-the box with dask.arrays. This makes it easier to write code that seamlessly works with either array type.
Note: the ufunc feature requires that you update NumPy to 1.13.0 or later. Packages are available through PyPI and conda on the defaults and conda-forge channels.
Asynchronous Clients
The Dask.distributed API is capable of operating within a Tornado or Asyncio event loop, which can be useful when integrating with other concurrent systems like web servers or when building some more advanced algorithms in machine learning and other fields. The API to do this used to be somewhat hidden and only known to a few and used underscores to signify that methods were asynchronous.
# Before
client = Client(start=False)
await client._start()
future = client.submit(func, *args)
result = await client._gather(future)
These methods are still around, but the process of starting the client has changed and we now recommend using the fully public methods even in asynchronous situations (these used to block).
# Now
client = await Client(asynchronous=True)
future = client.submit(func, *args)
result = await client.gather(future) # no longer use the underscore
You can also await futures directly:
result = await future
You can use yield instead of await if you prefer Python 2.
More information is available at https://distributed.readthedocs.org/en/latest/asynchronous.html.
Single-threaded scheduler moves from dask.async to dask.local
The single-machine scheduler used to live in the dask.async module. With
async becoming a keyword since Python 3.5 we’re forced to rename this. You
can now find the code in dask.local. This will particularly affect anyone
who was using the single-threaded scheduler, previously known as
dask.async.get_sync. The term dask.get can be used to reliably refer to
the single-threaded base scheduler across versions.
Retired the distributed.collections module
Early blogposts referred to functions like futures_to_dask_array which
resided in the distributed.collections module. These have since been
entirely replaced by better interactions between Futures and Delayed objects.
This module has been removed entirely.
Always create new directories with the –local-directory flag
Dask workers create a directory where they can place temporary files.
Typically this goes into your operating system’s temporary directory (/tmp on
Linux and Mac).
Some users on network file systems specify this directory explicitly with the
dask-worker ... --local-directory option, pointing to some other better place
like a local SSD drive. Previously Dask would dump files into the provided
directory. Now it will create a new subdirectory and place files there. This
tends to be much more convenient for users on network file systems.
$ dask-worker scheduler-address:8786 --local-directory /scratch
$ ls /scratch
worker-1234/
$ ls /scratch/worker-1234/
user-script.py disk-storage/ ...
Bag.map no longer automatically expands tuples
Previously the map method would inspect functions and automatically expand
tuples to fill arguments:
import dask.bag as db
b = db.from_sequence([(1, 10), (2, 20), (3, 30)])
>>> b.map(lambda x, y: return x + y).compute()
[11, 22, 33]
While convenient, this behavior gave rise to corner cases and stopped us from being able to support multi-bag mapping functions. It has since been removed. As an advantage though, you can now map two co-partitioned bags together.
a = db.from_sequence([1, 2, 3])
b = db.from_sequence([10, 20, 30])
>>> db.map(lambda x, y: x + y, a, b).compute()
[11, 22, 33]
Styling
Clients and Futures have nicer HTML reprs that show up in the Jupyter notebook.
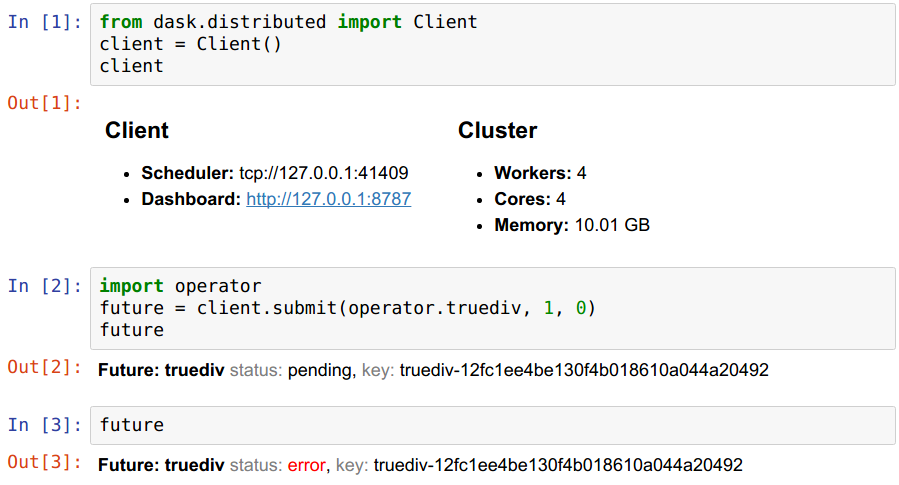
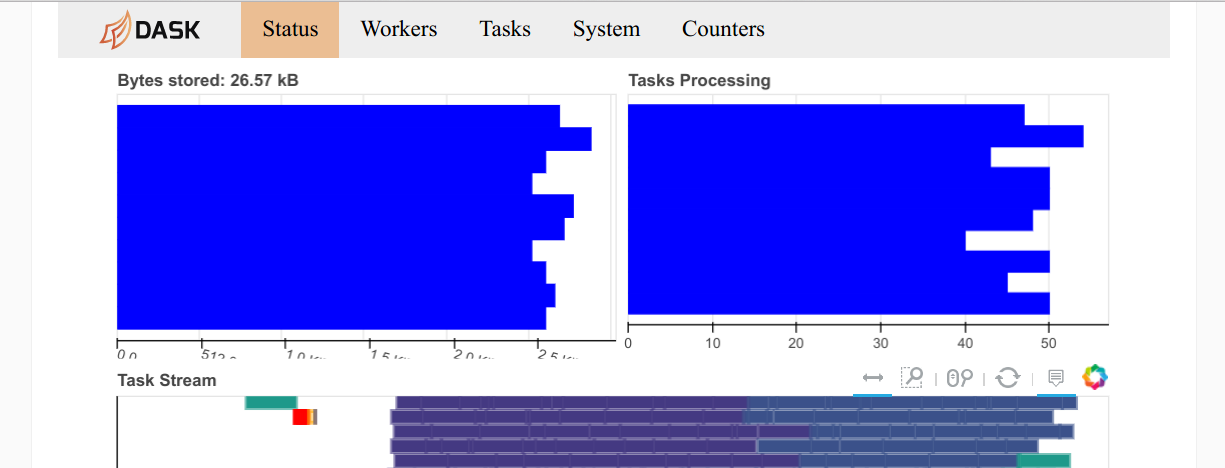
And the dashboard stays a decent width and has a new navigation bar with links to other dashboard pages. This template is now consistently applied to all dashboard pages.
Multi-client coordination
More primitives to help coordinate between multiple clients on the same cluster have been added. These include Queues and shared Variables for futures.
Joblib performance through pre-scattering
When using Dask to power Joblib
computations (such as occur in Scikit-Learn) with the joblib.parallel_backend
context manager, you can now pre-scatter select data to all workers. This can
significantly speed up some scikit-learn computations by reducing repeated data
transfer.
import distributed.joblib
from sklearn.externals.joblib import parallel_backend
# Serialize the training data only once to each worker
with parallel_backend('dask.distributed', scheduler_host='localhost:8786',
scatter=[digits.data, digits.target]):
search.fit(digits.data, digits.target)
Other Array Improvements
- Filled out the dask.array.fft module
- Added a basic dask.array.stats module with functions like
chisquare - Support the
@matrix multiply operator
General performance and stability
As usual, a number of bugs were identified and resolved and a number of performance optimizations were implemented. Thank you to all users and developers who continue to help identify and implement areas for improvement. Users should generally have a smoother experience.
Removed ZMQ networking backend
We have removed the experimental ZeroMQ networking backend. This was not particularly useful in practice. However it was very effective in serving as an example while we were making our network communication layer pluggable with different protocols.
Related Releases
The following related projects have also been released recently and may be worth updating:
- NumPy 1.13.0
- Pandas 0.20.2
- Bokeh 0.12.6
- Fastparquet 0.1.0
- S3FS 0.1.1
- Cloudpickle 0.3.1 (pip)
- lz4 0.10.0 (pip)
Acknowledgements
The following people contributed to the dask/dask repository since the 0.14.3 release on May 5th:
- Antoine Pitrou
- Elliott Sales de Andrade
- Ghislain Antony Vaillant
- John A Kirkham
- Jim Crist
- Joseph Crail
- Juan Nunez-Iglesias
- Julien Lhermitte
- Martin Durant
- Matthew Rocklin
- Samantha Hughes
- Tom Augspurger
The following people contributed to the dask/distributed repository since the 1.16.2 release on May 5th:
- A. Jesse Jiryu Davis
- Antoine Pitrou
- Brett Naul
- Eugene Van den Bulke
- Fabian Keller
- Jim Crist
- Krisztián Szűcs
- Matthew Rocklin
- Simon Perkins
- Thomas Arildsen
- Viacheslav Ostroukh
blog comments powered by Disqus